- Полное прохождение
- Глава 1: Деревня Калим
- Глава 2: Гебет
- Глава 4: Казарма Стражей
- Глава 5: Святой город Аратум
- Глава 6: Осада (часть 1)
- Глава 7: Осада (часть 2)
- Глава 8: Глубинный лес
- Глава 9: Исконная кузница
- Глава 10: Забытые равнины
- Глава 11: Перелом
- Глава 12: Командный пункт Стражей
- Глава 13: Из иного мира
- Глава 14: Шпиль Нератула
- Глава 15: Город Райуул
- Глава 16: Болота КарТула
- Глава 17: Храм Ломарит
- Глава 18: Чрево зверя
- Глава 19: Пристанище душ
- Глава 20: Воскрешение
- Глава 22: Возмездие
- Все квесты и их прохождение
- Все рецепты алхимии
- Все скрытые перки
- Все загадки Вотрубы
- Карта батрака Вашека
- Карта видлакских разбойников
- Карта утопленника
- Карта Желеевских болот
- Карта лесорубов из Нижнего Семина
- Оставшаяся от мертвеца карта
- Карта слатейовских охотничьих угодий
- Карта пойманного вора
- Карта контрабандиста
- Карта Боржика
- Хижина дикой бабы
- Хижина водяного
- Перевернутая телега
- Где найти лопату?
- Как получить лошадь?
- Интерактивная карта
- Странные вирши
- Штольня под Тросками
- Два мертвых дерева
- Промокоды
- Тир-лист персонажей
- Баннеры 1.2
- Тир-лист банбу
- Инспектор Мяучело
- Памятные монеты АИК
- Пропавшие мини-грузовики
- Все скрытые квесты
- Все достижения
- Все арты c6 персонажей
- Как повысить уровень доверия агентов?
- Клякса: как приручить?
- Видеопрокат и все видеокассеты
- Отдыхающая домохозяйка: фильм
- Ностальгирующая девушка: фильм
- Влюбленная девушка: фильм
- Квест Клуб загадочников 1 и 2
- Квест Отмотай назад, детектив
- Квест Заметание секретов
- Квест Пропавшая картина
- Квест Бескрайняя бездна
- Квест Пророчество
- Квест Лимб банбу
- Все гайды
- Испытания Мерлина
- Хранилища сокровищ
- Луны мистера Муна
- Хитроумные ключи
- Головоломки Иродианы
- Квест «Призрак нашей любви»
- Квест «Колодец, колодец»
- Квест «Сокровища из проклятой гробницы»
- Квест «Гиппогриф вам укажет путь»
- Квест «Словно по звонку»
- Непростительные заклинания
- Все легендарные сундуки
- Все животные и твари
- Все метлы
- Все концовки
- Все гайды
- Башня Рамазита и колдовской погреб
- Вызов Шар — все испытания и Копье Ночи
- Логово Ансура — все чертоги и дракон
- Литейная стальной стражи — как спасти гондийцев
- Обыскать подвал — как открыть Некромантию Тхая
- Разрушенная башня — как запустить лифт
- Адамантиновая кузня — все формы и мифриловая руда
- Завершить оружейный шедевр — кора суссура
- Тетушка Этель — как спасти Майрину
- Яйцо гитьянки — как украсть и можно ли вырастить
- Мистический Падальщик — где найти слугу
- Найти клоуна Каплю — все части тела
- Как победить Геррингот Торм?
- Где найти Кровь Латандера?
- Где найти Песню Ночи?
- Все гайды
- Промокоды Honkai Star Rail
- Все сундуки Золотого мига в Honkai Star Rail
- Похвала высокой морали в Honkai Star Rail
- Все сундуки в Лофу Сяньчжоу из Honkai Star Rail
- Первооткрыватель в Honkai Star Rail
- Все сундуки Сада безмятежности в Honkai Star Rail
- Беглецы в Доме кандалов
- Заказ прокси
- Дом кандалов: сундуки и робоптахи
- Гексанексус: Remake в ХСР

OpenAI: если отучать ИИ хитрить, то он хитрит хитрее
У исследователей уже есть мысли на этот счет.

OpenAI и Apollo Research опубликовали исследование, посвященное попыткам предотвращения обмана со стороны нейросетей. Иногда ИИ вроде бы ведет себя корректно, но на самом деле обманывает пользователя или преследует свои цели, и с этим надо что-то делать.
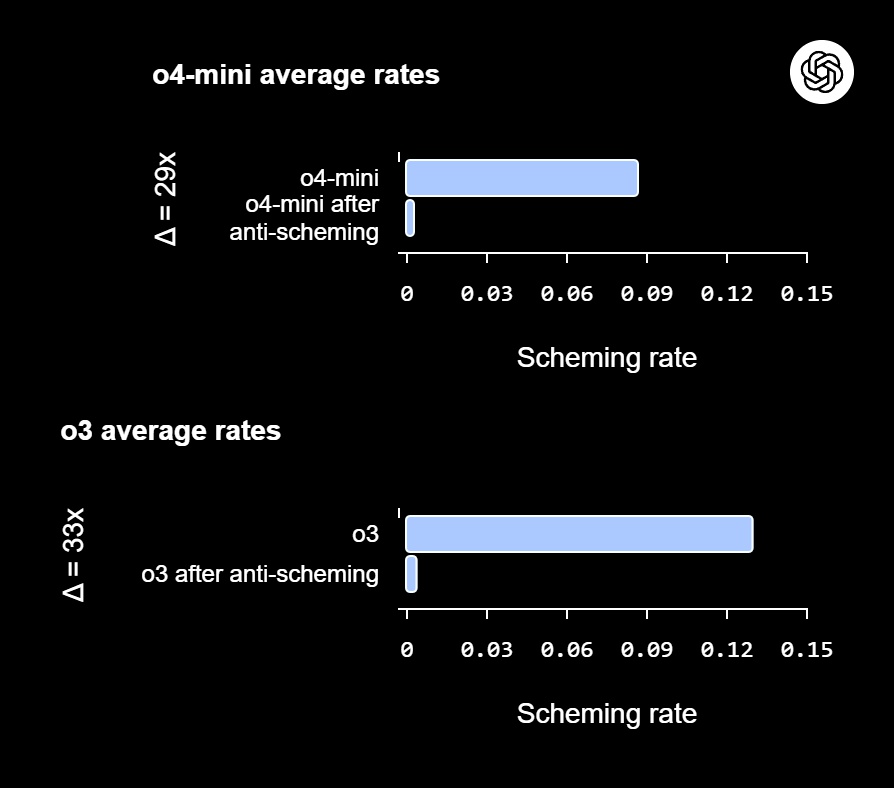
Исследователи обнаружили, что попытки отучить нейросети от «схематоза» традиционными методами зачастую неэффективны. Более того: такое обучение может привести к тому, что ИИ начнет действовать изощреннее, лучше скрывая свои истинные намерения.
Оказалось, что если модель осознает факт проверки, то она может притворяться честной лишь для прохождения теста. В таких случаях ИИ становится внимательнее просто из-за осознания наблюдения, а не из-за реального изменения мотивации.
Интересный момент: хотя ИИ и может обманывать, чаще всего речь идет о мелких нарушениях. Например, нейросеть говорит об успешно выполненной задаче, когда на самом деле задача не выполнена.
В OpenAI и Apollo Research считают, что нашли довольно эффективный метод противостояния обману со стороны ИИ: deliberative alignment. Его суть заключается в том, что модель сначала изучает и повторяет правила, нацеленные на предотвращение обмана, а затем приступает к выполнению задачи.
Такой подход позволил значительно снизить количество случаев манипулирования со стороны нейросетей. В OpenAI считают, что в будущем deliberative alignment может быть очень полезен: по мере увеличения сложности задач и самостоятельности ИИ-агентов серьезных негативных последствий обмана будет расти.
- СМИ: OpenAI готовит целый спектр устройств — от умной колонки до очков и пина
- ИИ-агента ChatGPT использовали для кражи данных из Gmail
- Конфликты выйдут наружу: астрологический прогноз на 21 сентября
- Intel не откажется от выпуска своих видеокарт из-за партнерства с Nvidia
- ChatGPT научат определять возраст и спрашивать документы пользователя
- СМИ: OpenAI хочет зарабатывать $200 миллиардов в год к 2030 году, но пока денег нет
